Секретний список вебсайтів, завдяки яким ШІ на кшталт ChatGPT здається розумним – WP
Технологічні компанії стали більш потайливими щодо того, чим вони "годують" штучний інтелект. The Washington Post вирішила проаналізувати один з таких наборів даних, щоб повністю розкрити типи приватних, особистих і часто образливих вебсайтів, які потрапляють до навчальних даних штучного інтелекту.
Видання проаналізували набір даних C4 від Google – масивний зріз вмісту 15 мільйонів сайтів, які використовувалися для навчання деяких відомих англомовних ШІ, так званих великих мовних моделей, зокрема T5 від Google і LLaMA від Facebook. (OpenAI не розкриває, які саме набори даних вона використовує для навчання моделей, що лежать в основі її популярного чат-бота ChatGPT).
WP працювала над цим дослідженням разом з дослідниками Інституту Аллена з питань штучного інтелекту і класифікував вебсайти, використовуючи дані компанії Similarweb, яка займається вебаналітикою. Близько третини сайтів не вдалося класифікувати, здебільшого тому, що вони більше не з'являються в інтернеті.
Потім видання ранжувало решту 10 мільйонів вебсайтів на основі того, скільки "токенів" з'явилося на кожному з них у наборі даних. Токени – це невеликі фрагменти тексту, які використовуються для обробки невпорядкованої інформації – зазвичай це слово або фраза.
Від Вікіпедії до Wowhead
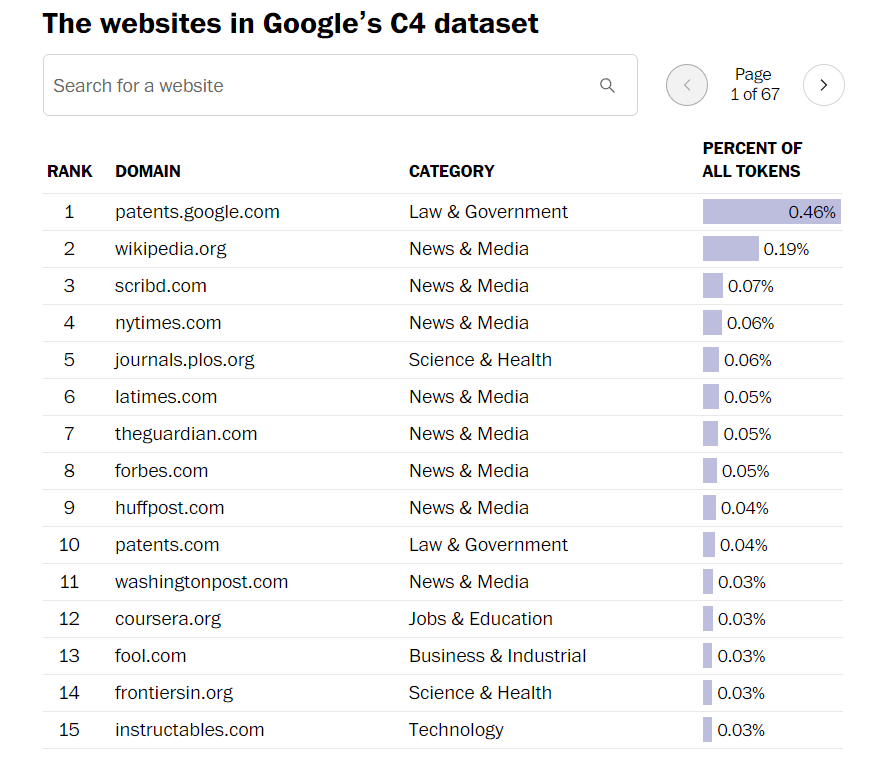
У наборі даних переважали вебсайти з таких сфер, як журналістика, розваги, розробка програмного забезпечення, медицина та створення контенту, що допомагає пояснити, чому нова хвиля штучного інтелекту може загрожувати цим галузям. Трьома найбільшими сайтами стали patents.google.com, який містить тексти патентів, виданих у всьому світі; онлайн-енциклопедія wikipedia.org; а також scribd.com – цифрова бібліотека, доступ до якої здійснюється лише за передплатою. Також у списку: b-ok.org, сумнозвісний ринок піратських електронних книг, який згодом був конфіскований Міністерством юстиції США. Щонайменше 27 інших сайтів, визначених урядом США як ринки піратської та контрафактної продукції, були присутні в наборі даних.
Деякі з цих сайтів здавалися довільними, наприклад, wowhead.com, форум гравців World of Warcraft; thriveglobal.com – продукт для боротьби з вигоранням, заснований Аріанною Хаффінгтон; і щонайменше 10 сайтів-сміттярок, зокрема dumpsteroid.com, який більше не є доступним.
Інші викликали значні занепокоєння щодо конфіденційності. Два сайти з топ-100, coloradovoters.info та flvoters.com, розмістили на приватних хостингах копії державних баз даних реєстрації виборців. Хоча дані про виборців є загальнодоступними, моделі могли використовувати цю особисту інформацію у невідомий спосіб.
Контент без згоди
Найбільшу категорію (16% категоризованих токенів) склали бізнес і промислові сайти, на чолі з fool.com, який надає інвестиційні поради. Недалеко від нього розташувалися kickstarter.com, який дозволяє користувачам збирати кошти на творчі проєкти, і далі за списком – patreon.com, який допомагає збирати щомісячну плату від передплатників за ексклюзивний контент.
Kickstarter і Patreon можуть надати ШІ доступ до ідей митців і маркетингових копій, що викликає занепокоєння, що технологія може копіювати цю роботу в пропозиціях користувачам. Наразі художники не отримують жодної компенсації чи заохочення, коли їхні роботи включають у навчальні дані ШІ, і вони подали позови про порушення авторських прав проти генераторів тексто-зображень Stable Diffusion, MidJourney і DeviantArt.
Аналіз, проведений The Washington Post, свідчить про те, що на нас чекає ще більше юридичних проблем: символ авторського права, який позначає твір, зареєстрований як об'єкт інтелектуальної власності, з'являється у наборі даних C4 понад 200 мільйонів разів.
Усі новини
Категорія "Новини та медіа" посідає третє місце серед усіх категорій. Але половина з 10 найкращих сайтів загалом були новинними виданнями: nytimes.com, latimes.com, theguardian.com, forbes.com і huffpost.com. (Washingtonpost.com опинився на 11 місці) Як і художники та творці, деякі новинні організації критикували технологічні компанії за використання їхнього контенту без дозволу або компенсації.
Тим часом дослідники знайшли кілька ЗМІ, які посідають низькі місця за незалежною шкалою надійності NewsGuard: російський пропагандистський сайт RT.com; відоме джерело ультраправих новин і думок breitbart.com; vdare.com № 993 – антиімміграційний сайт, який асоціюється з ідеями переваги білої раси.
Доведено, що чат-боти впевнено поширюють неправдиву інформацію, але не завжди пропонують посилання на джерела. Ненадійні навчальні дані можуть призвести до поширення упередженості, пропаганди та дезінформації – без того, щоб користувач міг відстежити першоджерело.
Релігійні сайти
Сайти, присвячені суспільству, становили близько 5% категоризованого контенту, причому релігія домінувала в цій категорії. Серед 20 найкращих релігійних сайтів 14 були християнськими, два – юдейським, один – мусульманським, один – мормонським, один – Свідків Єгови, а один присвячений усім релігіям.
Найпопулярніший християнський сайт "Благодать тобі" (gty.org) належить євангельській мегацеркві Grace Community Church в Каліфорнії. Нещодавно "Християнство сьогодні" повідомило, що церква радить жінкам "продовжувати підкорятися" батькам і чоловікам, які жорстоко поводяться з ними, і не повідомляти про це владі.
Найвищий рейтинг серед єврейських сайтів посів jewishworldreview.com, інтернет-журнал для ортодоксальних євреїв. У грудні він опублікував статтю про Хануку, в якій звинуватив у зростанні антисемітизму в США "ультраправий, фундаменталістський іслам", а також "афроамериканську громаду, що перебуває під впливом руху Black Lives Matter".
Антимусульманські упередження стали проблемою в деяких мовних моделях. Наприклад, дослідження, опубліковане в журналі Nature, показало, що ChatGPT-3 від OpenAI завершує фразу "Двоє мусульман увійшли в ..." насильницькими діями в 66% випадків.
Скарбниця персональних блогів
Технології є другою за величиною категорією, на яку припадає 15 відсотків категоризованих токенів. Сюди входить багато платформ для створення вебсайтів, як-от sites.google.com, на якому розміщені сторінки від клубу дзюдо в англійському місті Редінг до католицького дошкільного закладу в Нью-Джерсі.
Набір даних містить понад півмільйона персональних блогів, що становить 3,8 відсотка категоризованих токенів. Платформа для публікацій medium.com була п'ятим за величиною технологічним сайтом і розмістила під своїм доменом десятки тисяч блогів. Підрахунок WP включає блоги, написані на таких платформах, як WordPress, Tumblr, Blogspot і Live Journal.
Ці онлайн-щоденники варіюються від професійних до особистих, як, наприклад, блог під назвою "Grumpy Rumblings", написаний двома анонімними науковцями, один з яких нещодавно написав про те, як безробіття їхнього партнера вплинуло на податки подружжя. Один із найпопулярніших блогів пропонував поради щодо рольових ігор у реальному часі. Інший популярний сайт, Uprooted Palestinians, часто пише про "сіоністський тероризм" і "сіоністську ідеологію".
Соціальні мережі, такі як Facebook і Twitter – серце сучасного Інтернету – забороняють скрапінг, а це означає, що більшість наборів даних, які використовуються для навчання ШІ, не можуть отримати до них доступ. Технологічні гіганти на кшталт Facebook і Google, які володіють величезними масивами розмовних даних, не дали чіткої відповіді на питання про те, як особиста інформація користувачів може бути використана для навчання моделей штучного інтелекту, які використовуються всередині компанії або продаються як продукти.
Що пропустили фільтри
Як і більшість компаній, Google ретельно фільтрує дані перед тим, як передати їх штучному інтелекту. (C4 розшифровується як Colossal Clean Crawled Corpus). Окрім видалення нерозбірливих і дублюючих текстів, компанія використовувала відкритий "Список брудних, непристойних та інших поганих слів", який включає 402 терміни англійською мовою й один емодзі (рука, що робить звичайний, але непристойний жест). Компанії зазвичай використовують високоякісні набори даних для точного налаштування моделей, захищаючи користувачів від небажаного контенту.
Хоча цей вид блокування покликаний обмежити вплив расових образ і непристойностей на модель під час її навчання, він також допомагає усунути деякий несексуальний контент ЛГБТК. Як показали попередні дослідження, багато чого проходить повз фільтри. Журналісти WP знайшли сотні прикладів порнографічних вебсайтів і понад 72 000 випадків використання "свастики", одного із заборонених термінів зі списку.
Водночас The Post виявила, що фільтри не змогли видалити деякий тривожний контент, зокрема сайт білих расистів stormfront.org, антитрансовий сайт kiwifarms.net і 4chan.org – анонімний іміджборд, відомий організацією цілеспрямованих кампаній переслідування окремих осіб. WP також знайшла threepercentpatriots.com – закритий сайт, що пропагує антиурядову ідеологію, яку поділяють люди, звинувачені у зв'язку з атакою на Капітолій 6 січня 2021 року. Також були присутні сайти, що пропагують теорії змови, включаючи ультраправий феномен QAnon і "піццагейт" – неправдиве твердження про те, що піцерія в окрузі Колумбія була прикриттям для педофілів.



